In the exciting world of Artificial Intelligence, Vision-Language Modeling (VLM) plays a key role in helping computers understand and describe images using natural language. My project focuses on creating a system that can automatically generate descriptive captions for images, making it easier for machines to communicate what they "see."
The main goal of this project was to develop an intelligent model that can look at an image and produce a relevant and accurate caption, such as "A cat sitting on a window sill." To achieve this, I utilized Transformers, a type of advanced machine learning model known for its ability to handle both visual and textual data effectively.
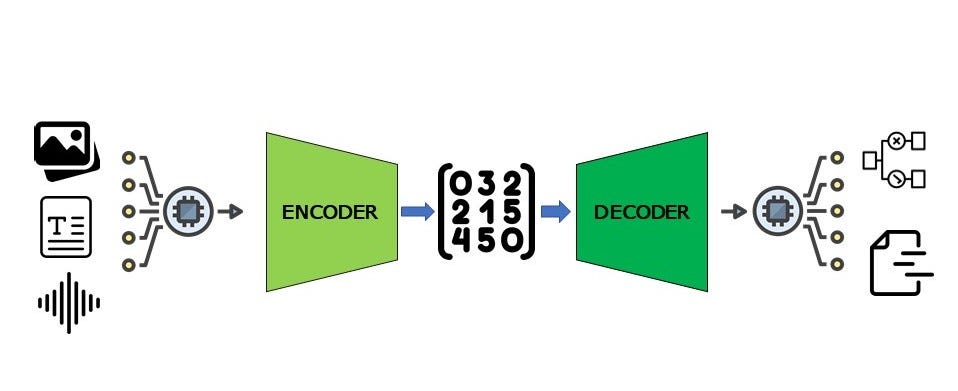
Using Python and PyTorch, I built a VisionEncoderDecoderModel that combines a Vision Transformer (ViT) for analyzing images with a BART tokenizer for generating text. This combination allows the model to process visual information and translate it into coherent sentences. I started by preparing a set of images paired with their corresponding captions, which the model used to learn how to connect visual elements with descriptive language.
Throughout the project, I focused on designing a neural network that could accurately interpret the details in an image and articulate them in a clear and meaningful way. By training the model with this data, it learned to recognize patterns and features within images and generate appropriate captions based on what it observed.
This project highlights my ability to work with both image and language data, showcasing skills in machine learning, neural network design, and the application of transformer-based models. It demonstrates how AI can bridge the gap between visual perception and language, enabling machines to describe the world in a way that is understandable and useful for humans.
View on Github